Artificial intelligence is increasingly embedded in the software development lifecycle, Mozilla’s recent integration of Anthropic’s Mythos Preview model to identify and remediate 271 security vulnerabilities in Firefox 150 represents a watershed moment. From a cybersecurity academic standpoint, this collaboration underscores both the transformative potential of frontier AI in static code analysis and the profound privacy and security risks that accompany its adoption. While the Firefox team acknowledges that emerging AI capabilities will not fundamentally upend cybersecurity in the long term, they rightly warn of a “rocky transition” for developers. This article examines the case through the dual lenses of privacy preservation and cyber risk management, drawing on established frameworks such as the NIST Cybersecurity Framework, OWASP AI Security guidelines, and scholarly debates on AI-augmented threat modeling.
The Mozilla-Anthropic Collaboration: Context and Outcomes
Mozilla’s Firefox browser, an open-source cornerstone of web privacy, has long prioritized security hardening. In early 2026, the team leveraged early access to Anthropic’s Mythos Preview—via direct collaboration rather than full participation in the broader Project Glasswing consortium—to scan the Firefox codebase. This followed an earlier pilot with Anthropic’s Opus 4.6 model, which surfaced 22 security-sensitive issues in Firefox 148. Mythos Preview, however, delivered a dramatically larger yield: 271 vulnerabilities patched in the Firefox 150 release. These included zero-days that, while discoverable by elite human researchers, would have remained latent without AI-assisted global semantic reasoning over the massive codebase.
Firefox CTO Bobby Holley described the experience as inducing “vertigo,” noting that “defenders finally have a chance to win, decisively.” Yet the scale of findings highlights a critical academic insight: modern codebases contain finite but previously intractable defect surfaces. Traditional fuzzing and manual red-teaming have always been resource-constrained; Mythos demonstrated that large language models (LLMs) trained for cybersecurity reasoning can now approximate—and in volume exceed—human-level vulnerability discovery at scale.
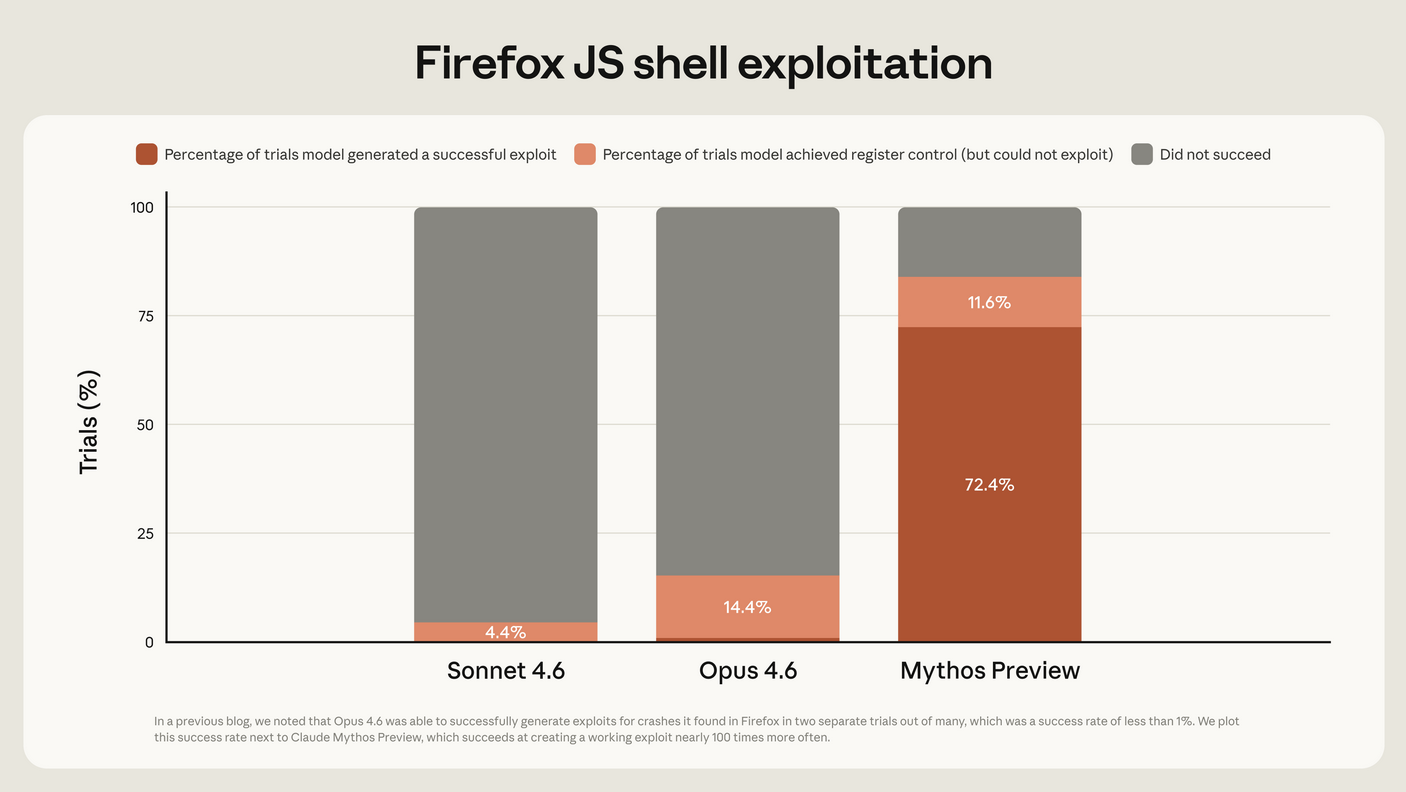
Technical Foundations of Mythos in Vulnerability Hunting
How Mythos Differs from Conventional Tools
Unlike rule-based static analyzers or coverage-guided fuzzers, Mythos Preview employs advanced multimodal reasoning over source code, dependencies, and architectural patterns. It identifies not only memory-safety issues (e.g., buffer overflows) but also logic flaws, race conditions, and subtle cryptographic misconfigurations that evade traditional tools. Mozilla reported that every Mythos-discovered bug could theoretically have been found by top-tier human analysts—yet the AI surfaced them in a single evaluation pass, compressing months of work into days.
From an academic perspective, this aligns with recent research in program analysis (e.g., papers on LLM-driven symbolic execution). However, it also raises questions about reproducibility and explainability: academic audits of AI outputs often reveal non-deterministic behavior, where slight prompt variations yield divergent results.
Cybersecurity Risks in the Age of AI-Assisted Development
The dual-use nature of Mythos-like models introduces asymmetric risks. Attackers—state-sponsored or criminal—will inevitably gain access to comparable capabilities, eroding the defender’s temporary advantage. Mozilla’s proactive patching is laudable, yet it exposes broader ecosystem vulnerabilities. Over-reliance on third-party AI may create new attack vectors, including model poisoning or adversarial prompting that injects subtle backdoors during analysis.
Numbered List: Key Cybersecurity Risk Vectors
- Supply-Chain Compromise of AI Models: Feeding an entire browser codebase to Anthropic’s infrastructure means trusting a third-party provider’s security posture. Any breach or insider threat at Anthropic could expose Firefox’s architectural secrets, even if the code is open-source.
- False-Negative Blind Spots: While Mythos matched elite humans on known bug classes, novel attack surfaces (e.g., AI-generated side-channel exploits in future Firefox features) may evade detection if training data lags behind emerging threats.
- Amplification of Legacy Debt: Older modules in Firefox, written pre-AI era, now face exhaustive scrutiny. Fixing 271 issues simultaneously risks regression bugs if patch validation is not rigorously automated.
- Adversarial Use by Threat Actors: Once Mythos-class models proliferate, ransomware groups or APTs can scan open-source dependencies at negligible cost, targeting unmaintained forks or smaller projects lacking Mozilla’s resources.
- Resource Exhaustion for Maintainers: The “firehose of bugs” Holley referenced demands significant engineering bandwidth, potentially diverting focus from privacy-enhancing features like enhanced tracking protection.
Privacy Implications: Data Sovereignty and Third-Party AI Exposure
Privacy risks extend beyond traditional confidentiality. Firefox’s codebase contains logic governing user data flows—cookie handling, telemetry opt-outs, and anti-fingerprinting mechanisms. Submitting this to an external LLM introduces novel governance challenges under frameworks like GDPR, CCPA, and emerging AI Acts.
- Codebase Exfiltration Risk: Even anonymized, the full context provided to Mythos could inadvertently leak proprietary implementation details or user-behavior heuristics that privacy advocates scrutinize.
- Model Memorization and Inference Attacks: LLMs are prone to training-data regurgitation; future versions of Mythos trained on scanned codebases might allow reconstruction of sensitive Firefox internals via prompt injection.
- Third-Party Data Residency Concerns: Anthropic’s infrastructure location and compliance with U.S. surveillance laws (e.g., CLOUD Act) raise jurisdictional issues for a privacy-first browser like Firefox, used globally by activists and journalists.
- Indirect User Privacy Erosion: Patches derived from AI analysis may alter privacy boundaries in unforeseen ways if the model’s recommendations prioritize performance over strict data-minimization principles.
- Equity and Access Gaps: Smaller open-source projects cannot afford similar AI access, widening the privacy-security divide between well-resourced entities and volunteer maintainers.
Navigating the Rocky Transition: Developer and Organizational Challenges
The Firefox team’s assessment—that AI will not “upend cybersecurity long term” but will impose a difficult adjustment period—is empirically sound. Academic studies on technology adoption (e.g., diffusion of innovations theory) predict exactly this: an S-curve of initial disruption followed by stabilization. Yet the transition demands discipline. Holley noted that engineering leaders at large firms may reassign thousands of developers for six months, while open-source maintainers face existential strain.
Key challenges include integrating AI outputs into CI/CD pipelines, training teams on prompt engineering for security audits, and maintaining human oversight to avoid automation bias. Mozilla’s head start positions Firefox favorably, but the broader ecosystem risks fragmentation if smaller projects lag.
Long-Term Outlook: Toward Privacy-Preserving AI in Secure Development
Academically, the Mozilla case illustrates a paradigm shift from offensive-dominant to potentially balanced cybersecurity economics. By making vulnerability discovery cheap and comprehensive, AI erodes attackers’ asymmetric advantage. However, sustained privacy requires investment in on-premise or federated AI alternatives, homomorphic encryption for code analysis, and standardized audit protocols for LLM-assisted tooling.
Future research should prioritize “AI red-teaming” of the AI tools themselves—testing Mythos-class models for hallucinated fixes or privacy leaks. Mozilla’s transparency in sharing these results sets a benchmark; the community must now advocate for open standards that embed privacy-by-design into AI security pipelines.
In conclusion, Mozilla’s deployment of Anthropic’s Mythos is neither unalloyed triumph nor catastrophe. It exemplifies the disciplined grit required for the rocky transition ahead. From a cybersecurity academic viewpoint, the real test lies not in the number of bugs fixed today, but in whether the industry can govern AI tools to protect user privacy while fortifying the digital commons. Only through rigorous, evidence-based policy and continued open collaboration will defenders truly “win decisively” without compromising the foundational values of trust and confidentiality that define secure software. (Word count: 1,112)